为了节约成本,我尝试将本地 mbp m4 部署的模型投入生产环节。在部署过程中,发现了一个问题,就是 ollama 运行的模型服务的上下文长度限制为 4096,而日常使用的 MaaS 服务,通常提供 128k 的上下文长度,在 Cline 里面配置使用会报错。经过一番摸索,终于找到了设置 ollama 模型服务上下文长度的解决方案,记录在本文。

省流版结论
在 ollama 启动的环境配置中,设置 OLLAMA_CONTEXT_LENGTH=128000,即可修改上下文长度为 128k。
128k 的上下文长度,启动后会消耗 34GB 的内存,我的 mpb m4 只有 48GB 内存,所以,我把上下文长度设置为 64k,启动后,消耗 26GB 内存,勉强可以接受。
我是使用 brew 安装的 ollama,这里有个小坑,不能直接修改 ~/Library/LaunchAgents/homebrew.mxcl.ollama.plist。否则 brew services restart ollama 后会覆盖配置,无法生效。正确的做法是,修改 /opt/homebrew/opt/ollama/homebrew.mxcl.ollama.plist,然后 brew services restart ollama 即可。添加的内容如下:
1
2
3
4
5
6
7
8
9
| <key>EnvironmentVariables</key>
<dict>
<key>OLLAMA_FLASH_ATTENTION</key>
<string>1</string>
<key>OLLAMA_KV_CACHE_TYPE</key>
<string>q8_0</string>
<key>OLLAMA_HOST</key>
<string>0.0.0.0:18443</string>
</dict>
|
方法探索
我本地和在 L20 节点上运行部署的 ollama 是 0.11.4 版本,直接查看 ollama run 的帮助信息,并没有找到设置上下文长度的参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| $ ollama -v
ollama version is 0.11.4
$ ollama run --help
Run a model
Usage:
ollama run MODEL [PROMPT] [flags]
Flags:
--format string Response format (e.g. json)
-h, --help help for run
--hidethinking Hide thinking output (if provided)
--insecure Use an insecure registry
--keepalive string Duration to keep a model loaded (e.g. 5m)
--nowordwrap Don't wrap words to the next line automatically
--think string[="true"] Enable thinking mode: true/false or high/medium/low for supported models
--verbose Show timings for response
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_NOHISTORY Do not preserve readline history
|
方法一
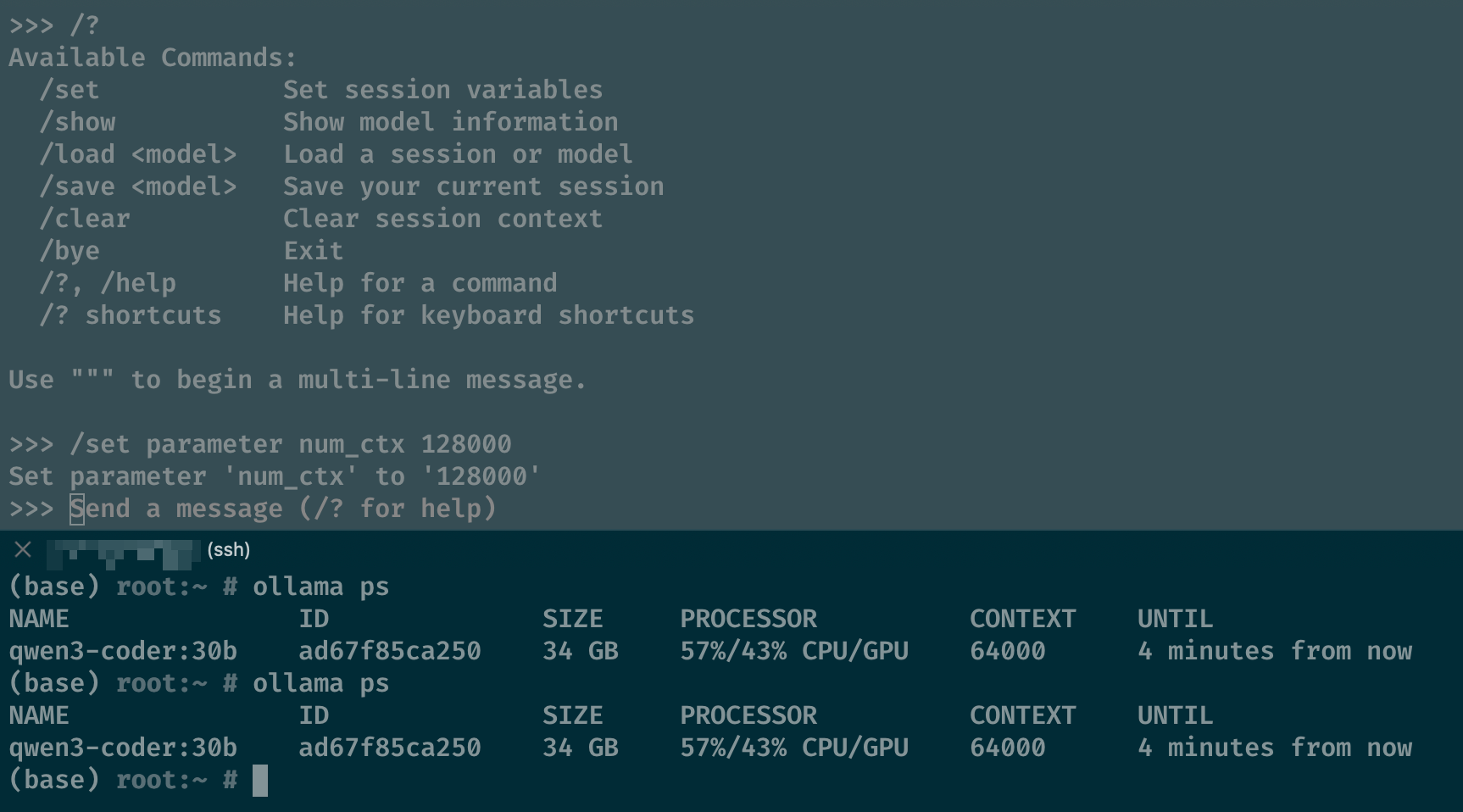
在 ollama 的 github 仓库中,有一个 issue 讨论了上下文长度的问题:可以通过 /set parameter num_ctx 128000 来设置上下文长度。我尝试了一下,发现可以设置,但是设置后,在终端通过 ollama ps 查看,显示的上下文长度还是 4096。
如果在 ollama 的 shell 中设置无效,那么我们通过 Modelfile 的方式,来设置上下文长度,是否会起作用呢?
首先,创建一个 Modelfile 文件,命令如下:
1
2
3
4
5
| cat > Modelfile << EOF
FROM qwen3-coder:30b
PARAMETER num_ctx 64000
EOF
|
然后,运行如下命令,构建并运行模型:
1
2
| $ ollama create -f Modelfile kofj/qwen3-coder:30b-64k-ctx
$ ollama run kofj/qwen3-coder:30b-64k-ctx
|
运行后,查看 ollama ps,显示的上下文长度为 64000,说明通过 Modelfile 设置上下文长度是有效的。
 但是,通过 Modelfile 设置上下文长度,需要重新构建模型,再重新运行,比较麻烦。有没有更简单的方法呢?
但是,通过 Modelfile 设置上下文长度,需要重新构建模型,再重新运行,比较麻烦。有没有更简单的方法呢?
方法二
问题解决了,但是方法实在有点蠢。要想知道有没有更简单的方法,我们先看看 ollama 的源码。对于模式的开源代码,通过大模型来研读,速度是相当快的。特别是我们只想构建对项目的整体认知,或者某个功能模块的实现,通过大模型,可以快速定位到关键代码,然后通过代码注释,快速了解代码的实现逻辑。
我使用 CodeBudy 和 Kimi-K2 大模型,对 ollama 的源码进行研读,很快定位到了设置上下文长度的代码。
我的提示词是:现在让我查找Ollama项目中如何使用envconfig.ContextLength()这个默认值,特别是在模型加载和Runner参数设置的地方。,大模型给出的结论如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
通过分析Ollama项目的源代码,我已经找到了当Modelfile中没有设置PARAMETER num_ctx时的默认上下文长度。
根据代码分析:
1. 默认上下文长度为4096 tokens
2. 这个默认值在以下位置定义:
在envconfig/config.go文件中,ContextLength = Uint("OLLAMA_CONTEXT_LENGTH", 4096)设置了环境变量的默认值为4096
在api/types.go文件的DefaultOptions()函数中,Runner.NumCtx被设置为int(envconfig.ContextLength()),即4096
3. 优先级机制:
如果Modelfile中设置了PARAMETER num_ctx <value>,则使用该值
如果没有设置,则使用环境变量OLLAMA_CONTEXT_LENGTH的值(默认为4096)
如果环境变量也没有设置,则最终使用4096作为默认值
4. 相关文档确认:
docs/modelfile.md文档中明确说明:"num_ctx | Sets the size of the context window... (Default: 4096)"
docs/faq.md文档也提到可以通过OLLAMA_CONTEXT_LENGTH环境变量来覆盖这个默认值
因此,当Modelfile中没有设置PARAMETER num_ctx时,Ollama使用的默认上下文长度是4096 tokens。
|
根据给出的信息后验,我实际检查涉及的代码 @envconfig/config.go 和 @api/types.go ,发现确实如此。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # envconfig/config.go
// ContextLength sets the default context length
ContextLength = Uint("OLLAMA_CONTEXT_LENGTH", 4096)
# api/types.go
Runner: Runner{
// options set when the model is loaded
NumCtx: int(envconfig.ContextLength()),
NumBatch: 512,
NumGPU: -1, // -1 here indicates that NumGPU should be set dynamically
NumThread: 0, // let the runtime decide
UseMMap: nil,
},
}
|
根据模型分析和我们后验得到的结论,我们可以通过设置环境变量 OLLAMA_CONTEXT_LENGTH 来设置上下文长度。于是,我尝试在 ollama shell 中设置环境变量,命令如下:
1
2
3
| (base) root:~ # export OLLAMA_CONTEXT_LENGTH=128000
(base) root:~ # export OLLAMA_CONTEXT_LENGTH=64000
(base) root:~ # nohup ollama start &
|
运行后,查看 ollama ps,显示的上下文长度为 64000,说明通过设置环境变量 OLLAMA_CONTEXT_LENGTH 来设置上下文长度是有效的。
总结
至此,我们解决了 ollama 本地部署模型上下文长度的问题。不过,这个环境变量设置是全局的,如果需要针对某个模型设置上下文长度,还需要进一步研究。